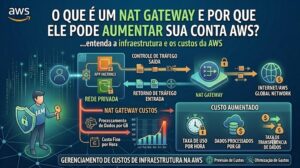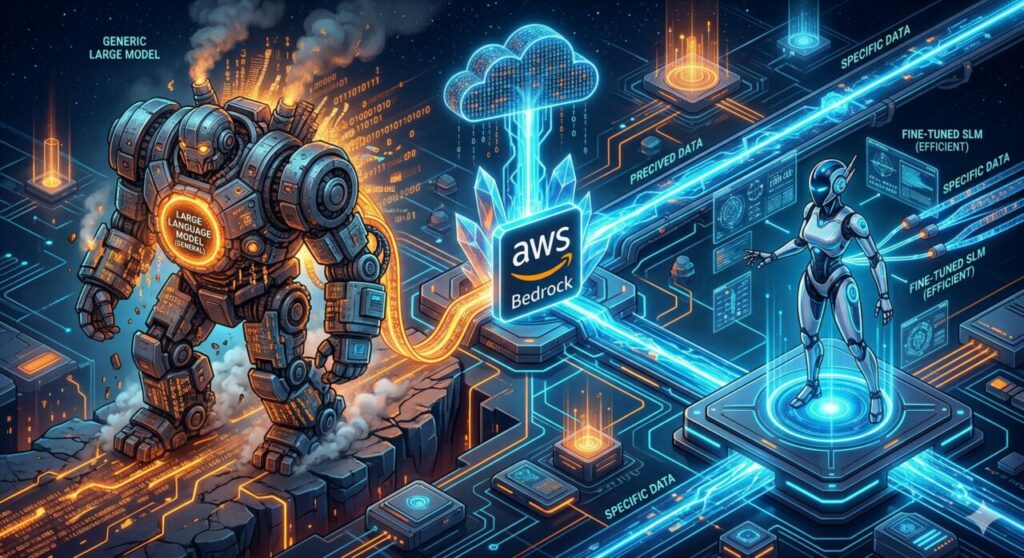
Fine-Tuning como o treinamento especializado de modelos menores supera os modelos genéricos em tarefas específicas, economizando até 60% no consumo de tokens.
A Síndrome da “Ferrari para ir à Padaria”
O ano de 2026 consolidou a Inteligência Artificial Generativa como o núcleo das operações de software corporativo. No entanto, o mercado está acordando para uma ressaca financeira perigosa. O padrão inicial da indústria foi utilizar modelos gigantescos (com trilhões de parâmetros) para resolver absolutamente qualquer problema, desde a geração de código complexo até a simples extração de entidades em uma nota fiscal.
Utilizar um Large Language Model (LLM) de ponta para classificar o sentimento de um ticket de suporte é o equivalente arquitetônico a usar uma Ferrari para ir à padaria: funciona, mas o custo operacional e o desperdício de energia são absurdos. O paradigma atual de FinOps para IA exige eficiência. É aqui que brilha o Amazon Bedrock Model Customization. Ao invés de pagar o prêmio por inferências em modelos gigantes, as empresas estão utilizando técnicas de Fine-Tuning (Ajuste Fino) em modelos menores, criando especialistas altamente eficientes que entregam a mesma precisão, com uma fração da latência e do custo.

O Dilema do Modelo Gigante vs. Modelo Especialista
Modelos fundacionais genéricos são treinados com grande parte do conhecimento da internet. Eles sabem escrever sonetos renascentistas e resolver equações de física quântica. Porém, se a sua aplicação é um assistente de triagem médica ou um classificador jurídico, esse “conhecimento extra” não gera valor de negócio; ele apenas aumenta o tempo de resposta (latência) e o custo de inferência.
A matemática financeira da IA é implacável. Modelos gigantes custam mais por milhão de tokens. Modelos menores (os chamados Small Language Models ou SLMs, na faixa de 8 a 70 bilhões de parâmetros, como Llama 3 8B ou Amazon Titan) são incrivelmente baratos e rápidos. O desafio sempre foi a precisão. O Fine-Tuning resolve isso ao injetar o vocabulário e o estilo específico do seu negócio diretamente nos “pesos” da rede neural do modelo menor, elevando sua performance na sua tarefa específica para níveis iguais ou superiores aos dos modelos gigantes genéricos.
Customização na Prática: Como o Bedrock Funciona
No passado, realizar o ajuste fino de um modelo exigia provisionar clusters de GPUs (instâncias EC2 P4 ou P5), configurar ambientes PyTorch complexos e gerenciar o ciclo de vida do treinamento manualmente.
O Amazon Bedrock transformou o Fine-Tuning em um serviço totalmente gerenciado. A plataforma utiliza técnicas modernas e eficientes em termos de parâmetros, como o LoRA (Low-Rank Adaptation). Em vez de reescrever todos os bilhões de parâmetros do modelo (o que seria caríssimo), o Bedrock congela o modelo original e treina apenas uma pequena camada adaptadora por cima dele. Isso reduz drasticamente o tempo de treinamento de semanas para apenas algumas horas, barateando o processo de customização de forma exponencial.
Segurança e Privacidade do Dado Proprietário
Quando falamos de treinar um modelo de IA com dados corporativos (histórico de chats de clientes, contratos sigilosos ou prontuários), a primeira objeção de qualquer CISO é a privacidade.
A arquitetura do Amazon Bedrock é blindada por design. Quando você inicia um trabalho de Model Customization, o processo ocorre inteiramente dentro da sua Virtual Private Cloud (VPC).
- Os dados de treinamento lidos do seu Amazon S3 nunca deixam a sua conta.
- A AWS garante contratualmente que os seus dados não são utilizados para treinar os modelos fundacionais globais base.
- O modelo resultante (o artefato customizado) é criptografado com as suas chaves do AWS KMS e é acessível única e exclusivamente pelos seus IDs de conta AWS.
Análise de FinOps: O Retorno sobre o Investimento
Migrar a arquitetura de Prompt Engineering em um modelo gigante para um Fine-Tuning em um modelo menor exige um investimento inicial de processamento, mas o retorno se paga rapidamente em escala.
| Métrica Avaliada | Modelo Gigante Genérico (On-Demand) | SLM Customizado via Bedrock |
| Custo por Milhão de Tokens | Elevado (Premium) | Baixo (Até 60% de redução) |
| Tamanho do Prompt Necessário | Longo (Muitos exemplos Few-Shot) | Curto (Zero-Shot, o modelo já aprendeu o formato) |
| Latência (Time to First Token) | Variável e geralmente maior | Ultrabaixa e consistente |
| Custo Fixo de Treinamento | Zero | Moderado (Custo das horas de job de Customization) |
Ao treinar o modelo para entender o formato de saída desejado (como um JSON perfeitamente estruturado), você elimina a necessidade de enviar dezenas de exemplos no prompt a cada requisição. Prompts menores significam menos tokens consumidos por chamada, multiplicando a economia em aplicações de alto tráfego.
O Workflow de Implementação de 2026
A jornada para colocar um modelo customizado em produção no Bedrock segue um pipeline limpo e determinístico:
- Preparação de Dados: Construa um dataset no formato JSONL (JSON Lines) contendo pares de
promptecompletionque representem o comportamento ideal que você deseja da IA. Armazene este arquivo em um bucket S3 seguro. - Criação do Job: No console do Bedrock (ou via AWS SDK), selecione o modelo base compatível, aponte para o seu bucket S3 e defina os hiperparâmetros (como Epochs e Learning Rate).
- Avaliação: O Bedrock executa o treinamento e gera métricas de validação para garantir que o modelo não está sofrendo de overfitting.
- Provisionamento: Uma vez aprovado, você adquire Provisioned Throughput para o seu modelo customizado e recebe um ARN (Amazon Resource Name) exclusivo para invocá-lo via API, exatamente como faria com um modelo público.
Conclusão
A maturidade em Inteligência Artificial não é medida pelo tamanho do modelo que você utiliza, mas pelo valor de negócio extraído em relação ao custo computacional investido. O Amazon Bedrock Model Customization democratizou a criação de IAs especialistas. Ao investir no Fine-Tuning de modelos menores para tarefas direcionadas, a sua engenharia reduz drasticamente a latência para o usuário final, fortalece a segurança da informação e corta até 60% da fatura de consumo de tokens. O futuro da IA corporativa não é genérico; ele é altamente especializado e implacavelmente eficiente.
Sobre a KXC Partner
A KXC Partner apoia empresas na evolução de sua maturidade em nuvem, com foco em governança, otimização de custos, segurança e automação.
Acompanhe nosso blog para mais conteúdos técnicos e estratégicos sobre AWS e transformação digital.