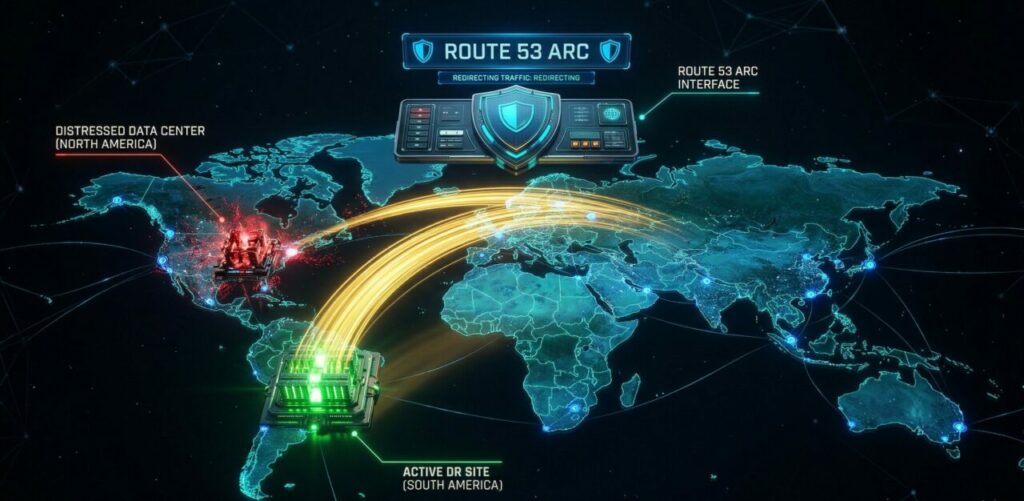
Route 53 ARC como utilizar verificações de prontidão e controles de roteamento para garantir um RTO próximo de zero em desastres regionais, superando as falhas do failover automatizado clássico.
A Ilusão da Alta Disponibilidade Simples
A promessa original da nuvem sempre foi a redundância. Projetar uma aplicação espalhada por três Zonas de Disponibilidade (Multi-AZ) resolve 99% das falhas de hardware ou rede localizadas. Contudo, arquiteturas de missão crítica — como sistemas bancários de core, gateways de pagamento e plataformas de saúde — exigem proteção contra aquele 1% estatístico: a falha completa ou a degradação sistêmica de uma Região AWS inteira (como um evento massivo em us-east-1 ou sa-east-1).
A solução padrão para esse nível de isolamento é a arquitetura Multi-Região, utilizando roteamento de failover baseado em DNS no Amazon Route 53. Mas existe um problema grave que empresas frequentemente descobrem da pior maneira: o failover de DNS puramente automatizado com base em verificações de integridade (Health Checks) pode piorar um incidente. Se a região de destino (Disaster Recovery) não tiver a capacidade computacional previamente escalada para absorver 100% do tráfego repentino, ela também cairá, causando uma falha em cascata catastrófica.

Para resolver a complexidade do tráfego global, a AWS desenvolveu o Route 53 Application Recovery Controller (ARC). O ARC entrega as ferramentas precisas para orquestrar recuperações de desastres previsíveis, transformando a esperança em garantia matemática.
A Falácia do Failover Automático e as “Gray Failures”
Os sistemas de monitoramento clássicos operam de forma binária: o servidor responde com código 200 (OK) ou código 500 (Erro). No entanto, o mundo real sofre de “Falhas Cinzentas” (Gray Failures). A região primária não cai totalmente; a latência simplesmente aumenta de forma sutil, as requisições de banco de dados começam a enfileirar e o sistema degrada lentamente.
Se um failover automático de DNS for acionado prematuramente no meio de uma flutuação de rede transitória (Flapping), o tráfego de milhões de usuários será jogado agressivamente entre continentes, corrompendo sessões e gerando inconsistência de dados em bancos como o Amazon Aurora Global Database. O ARC introduz o conceito de failover intencional e altamente controlado para mitigar esse risco de automação cega.
Readiness Checks: A Prova de Prontidão
Antes de virar a chave e mandar o tráfego para a região de contingência, você precisa de uma prova concreta de que a nova região suporta a carga. O ARC resolve isso com as Verificações de Prontidão (Readiness Checks).
O ARC monitora continuamente as quotas da AWS, os limites de infraestrutura e a configuração de capacidade nas regiões primária e de recuperação. Ele analisa profundamente seus recursos:
- Os limites do Auto Scaling Group na região de DR estão altos o suficiente?
- Os Application Load Balancers (ALBs) e o Amazon DynamoDB estão provisionados com capacidade simétrica à região principal?
- As regras de segurança de WAF estão espelhadas corretamente?
Se a região de recuperação não estiver perfeitamente alinhada e dimensionada, o ARC sinaliza que o ambiente não está “Pronto” (Not Ready), impedindo que a equipe de operações cometa o erro de executar um failover para um buraco negro de capacidade.
Routing Controls: O Interruptor Global de Segurança
A funcionalidade mais poderosa do ARC são os Controles de Roteamento (Routing Controls). Eles funcionam como interruptores on/off manuais ou programáticos sobre o fluxo de tráfego do Route 53.
Diferente de configurações normais de DNS que dependem do plano de controle (Control Plane) padrão do Route 53, os Routing Controls do ARC rodam em um cluster de plano de dados (Data Plane) altamente distribuído. Ele utiliza cinco endpoints regionais diferentes. Isso significa que, para acionar um failover durante um desastre grave, você não depende da saúde da região que já está falhando. Para que uma alteração de roteamento seja aceita, o sistema utiliza um algoritmo de consenso de Quorum, exigindo a confirmação de uma maioria de nós distribuídos globalmente. É o mais alto padrão de resiliência de engenharia de rede disponível em nuvem pública hoje.
Arquitetura Baseada em Células e Blast Radius
O Route 53 ARC facilita a implementação do padrão arquitetônico mais avançado de 2026: a Arquitetura Baseada em Células (Cell-Based Architecture).
Em vez de tratar uma região inteira como um bloco único, a aplicação é dividida em células independentes. Cada célula atende a uma fração do tráfego global. O ARC gerencia o tráfego no nível da célula. Se um deploy defeituoso corromper a Célula A, o ARC permite que você desvie rapidamente apenas o tráfego dos clientes afetados para a Célula B, reduzindo drasticamente o Raio de Explosão (Blast Radius). Essa granularidade transforma interrupções globais em pequenos contratempos localizados que duram segundos.
Execução do Plano de Recuperação de Desastres
Integrar o ARC ao seu runbook de DR muda a dinâmica da equipe de resposta a incidentes (SRE). O fluxo recomendado para alta criticidade é:
- O CloudWatch detecta anomalias graves (degradação sistêmica) na Região Primária e alerta os engenheiros de plantão.
- O engenheiro abre o painel do ARC e valida visualmente que as Readiness Checks da Região Secundária estão todas “Verdes” (sincronizadas e prontas para absorver carga).
- O engenheiro desabilita o Routing Control da Região Primária e habilita o da Região Secundária.
- Em virtude do motor do ARC, as rotas de DNS globais são atualizadas imediatamente e o tráfego começa a drenar para a região saudável, estabelecendo um Recovery Time Objective (RTO) na casa dos minutos ou segundos.
Conclusão
Alta disponibilidade em nível global não se atinge apenas provisionando instâncias EC2 em múltiplos continentes e configurando uma rota de DNS. Ela exige monitoramento simétrico contínuo e a capacidade de redirecionar o tráfego com garantia técnica e previsibilidade. O AWS Route 53 Application Recovery Controller é a ferramenta definitiva que separa as arquiteturas maduras das vulneráveis. Em caso de desastres, ele garante que você nunca mandará o tráfego dos seus clientes valiosos para um ambiente que não está perfeitamente pronto para recebê-los.
Sobre a KXC Partner
A KXC Partner apoia empresas na evolução de sua maturidade em nuvem, com foco em governança, otimização de custos, segurança e automação.
Acompanhe nosso blog para mais conteúdos técnicos e estratégicos sobre AWS e transformação digital.