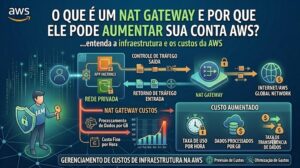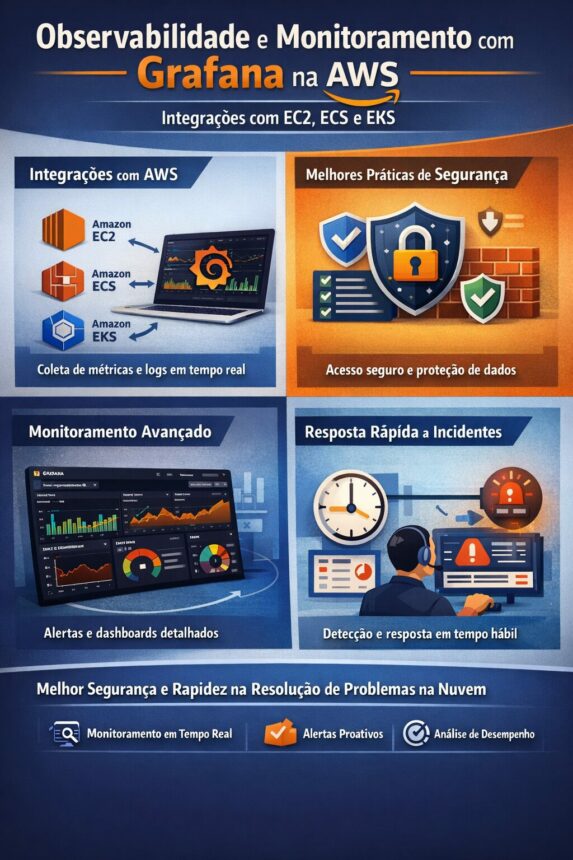
Quando a gente fala sobre monitoramento na AWS, muita gente imagina algo extremamente complexo, cheio de comandos e telas difíceis de entender. Mas, na prática, a ideia é bem mais simples: é conseguir enxergar o que está acontecendo nos seus servidores e aplicações antes que o problema fique grande demais.
Hoje, grande parte das empresas roda seus sistemas na Amazon Web Services. Isso inclui servidores virtuais com Amazon EC2, aplicações em containers usando Amazon ECS ou ambientes Kubernetes com Amazon EKS. Tudo isso funciona 24 horas por dia. E quando algo começa a sair do normal, o impacto pode ser imediato: lentidão, erro no sistema, cliente reclamando ou até perda financeira.
É nesse cenário que o Grafana entra como peça-chave.
Pense nele como um grande painel de controle. Em vez de precisar acessar cada servidor separadamente ou analisar arquivos técnicos cheios de informações difíceis de interpretar, você passa a ter gráficos organizados e claros. Uso de CPU, memória, tráfego de rede, quantidade de acessos, erros na aplicação — tudo concentrado em dashboards visuais.
Isso facilita muito a vida, principalmente em ambientes que crescem rápido. Quando se usa EC2, por exemplo, é possível acompanhar se alguma instância está sobrecarregada. No ECS, dá para monitorar containers que reiniciam com frequência ou serviços que estão consumindo mais recurso do que deveriam. No EKS, é possível acompanhar a saúde do cluster inteiro, incluindo nodes e pods.
Mas o Grafana não “adivinha” essas informações sozinho. Ele se conecta a outras ferramentas que fazem a coleta dos dados. Uma das integrações mais importantes é com o Prometheus.
O Prometheus é responsável por coletar métricas — que são basicamente números que mostram como o sistema está se comportando. Ele mede, por exemplo, quanto tempo uma API leva para responder, quantas requisições estão chegando por segundo ou qual é o percentual de erro de um serviço. Em ambientes Kubernetes, como no EKS, essa integração é muito comum, porque o Prometheus consegue coletar dados diretamente dos serviços e containers de forma automática.
Depois que essas métricas são coletadas, o Grafana organiza tudo em gráficos fáceis de entender. Você consegue visualizar tendências, comparar períodos e até prever quando algo pode virar problema.
Só que números contam apenas parte da história. Quando acontece uma falha, é importante entender o motivo. E é aí que entram os logs. Para isso, a integração com o Grafana Loki faz toda a diferença.
O Loki é uma solução voltada para centralizar e organizar logs. Ele coleta os registros gerados pelas aplicações e servidores e permite pesquisar neles de forma rápida. O grande benefício é poder cruzar informações: você vê no gráfico que a taxa de erro subiu às 14h32 e, no mesmo painel, consegue consultar os logs daquele horário específico.
Essa combinação entre métricas (Prometheus) e logs (Loki) dentro do Grafana reduz muito o tempo gasto tentando descobrir o que aconteceu. Em vez de ficar “caçando” informações em vários lugares, tudo está integrado.
Outro ponto importante é a segurança do monitoramento. Não adianta ter visibilidade se qualquer pessoa pode acessar os dados. Na AWS, é possível usar o AWS Identity and Access Management para controlar quem tem permissão para visualizar ou alterar dashboards. Isso garante que cada usuário tenha acesso apenas ao que realmente precisa.
Também é possível configurar autenticação segura, criptografia de comunicação e separar ambientes de produção, homologação e testes. Tudo isso ajuda a manter o monitoramento organizado e protegido.
Um benefício muito prático de ter essa estrutura funcionando é a melhoria no tempo de resposta a incidentes. Antes, muitas equipes só descobriam problemas quando alguém avisava que o sistema estava fora do ar. Hoje, é possível configurar alertas automáticos. Se o uso de CPU ultrapassar um limite, se a aplicação começar a retornar muitos erros ou se o tempo de resposta aumentar demais, o time é notificado imediatamente.
Isso muda completamente a forma de trabalhar. Em vez de agir apenas depois que o problema afeta o cliente, a equipe passa a agir de forma preventiva.
E não é necessário começar com algo extremamente complexo. O ideal é começar simples: monitorar recursos básicos, como CPU, memória e disponibilidade. Depois, incluir métricas de aplicação, logs detalhados e alertas mais específicos.
Com o tempo, o monitoramento deixa de ser apenas uma ferramenta técnica e passa a ser uma parte estratégica do negócio. Ele ajuda no planejamento de capacidade, na identificação de gargalos e até na tomada de decisão sobre investimentos em infraestrutura.
No final das contas, utilizar Grafana integrado com Prometheus e Loki na AWS é uma forma prática de ganhar visibilidade, segurança e agilidade. Não se trata apenas de acompanhar gráficos, mas de ter controle real sobre o ambiente. E quando você consegue enxergar claramente o que está acontecendo, resolver problemas deixa de ser um processo demorado e passa a ser algo muito mais rápido e organizado.