Como proteger dados sensíveis e evitar alucinações corporativas com Bedrock Guardrails sem comprometer a performance dos LLMs.
O Desafio da Confiança na IA
A fase de experimentação com Inteligência Artificial Generativa acabou. Em 2026, as empresas estão colocando agentes autônomos e assistentes de código de frente para os clientes e sistemas críticos. No entanto, essa adoção em massa esbarra em um obstáculo fundamental: a confiança. Como você garante que um modelo treinado com dados da internet inteira não vá ofender um cliente, vazar o CPF de um paciente ou sugerir o produto de um concorrente direto?
Até recentemente, a solução era tentar contornar esses riscos através de Prompt Engineering complexo (que os usuários facilmente burlam via Prompt Injection) ou gastar centenas de milhares de dólares fazendo o Fine-Tuning de modelos para “desaprender” comportamentos indesejados. O Amazon Bedrock Guardrails mudou esse paradigma. Ele atua como um escudo de segurança de infraestrutura, totalmente desacoplado do modelo fundacional, permitindo que as empresas apliquem políticas de governança rigorosas com latência de milissegundos.

A Mecânica da Interceptação Dupla
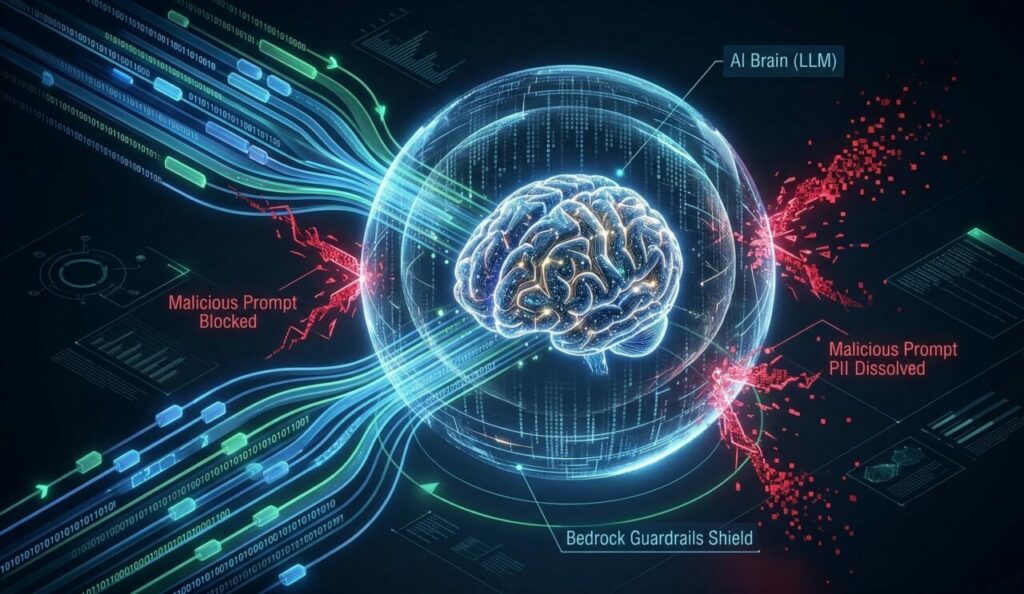
O grande diferencial arquitetônico dos Guardrails no Bedrock é a sua atuação bidirecional. O serviço não confia nem no usuário final, nem no próprio modelo de IA.
Quando uma requisição é feita pela sua aplicação, o fluxo ocorre em duas etapas de validação:
- Validação de Entrada (Pre-Inference): Antes do prompt do usuário sequer tocar no modelo (seja ele Claude 3.5, Llama 3 ou Amazon Titan), o Guardrail intercepta o texto. Ele varre a entrada em busca de tentativas de Jailbreak (ataques para burlar regras do sistema), injeção de comandos maliciosos ou tópicos estritamente proibidos pela empresa. Se detectado, o Bedrock bloqueia a chamada e retorna uma mensagem padrão configurada por você, economizando o custo de inferência (tokens) que seria gasto à toa.
- Validação de Saída (Post-Inference): Se a entrada for segura, o LLM processa a resposta. Antes de devolvê-la ao usuário, o Guardrail intercepta a saída. Ele verifica se o modelo “alucinou” dados, gerou linguagem tóxica ou incluiu Informações Pessoalmente Identificáveis (PII) que não deveriam ser expostas.
Detecção e Mascaramento de PII
Para os setores financeiro e de saúde, a proteção de dados é inegociável. O Bedrock Guardrails traz um motor de reconhecimento de padrões e Machine Learning treinado especificamente para identificar PII.
Você pode configurar a ferramenta para identificar dezenas de tipos de dados sensíveis (números de cartão de crédito, CPFs, endereços, e-mails). A grande vantagem operacional é a flexibilidade de ação. Você não precisa necessariamente bloquear a resposta inteira. O Guardrail pode aplicar um Mascaramento Automático. Se o modelo tentar responder “O saldo do cliente João Silva, CPF 123.456.789-00 é alto”, o Guardrail transforma isso em “O saldo do cliente [NOME-MASCARADO], CPF [CPF-MASCARADO] é alto” em tempo real, antes de chegar ao front-end.
Filtros de Tópicos e Palavras Restritas
Além da segurança dos dados, há a segurança da marca. Uma empresa de telecomunicações não quer que seu chatbot de suporte escreva um poema elogiando a operadora concorrente.
Com os filtros de tópicos (Denied Topics), você descreve em linguagem natural o que a IA está proibida de discutir (exemplo: “Não forneça conselhos de investimentos financeiros” ou “Não compare nossos produtos com a concorrência”). O Bedrock cria vetores semânticos baseados na sua descrição e bloqueia qualquer conversa que se desvie para esses caminhos, mantendo o agente estritamente focado no seu caso de uso de negócios.
Custo-Benefício: Guardrails vs Fine-Tuning
Arquitetos frequentemente debatem se devem treinar o modelo para ser seguro ou usar uma ferramenta externa. A tabela abaixo resume por que os Guardrails venceram essa disputa em operações de escala:
| Característica | Fine-Tuning para Segurança | Amazon Bedrock Guardrails |
| Custo de Implementação | Altíssimo (requer milhares de horas de GPU). | Baixo (configuração via console/API em minutos). |
| Agilidade de Atualização | Lenta (se uma nova ameaça surgir, exige re-treinamento). | Imediata (atualização da política JSON entra em vigor na hora). |
| Portabilidade | Preso a um modelo específico. | Agnóstico (a mesma política protege Llama, Claude e Titan). |
| Eficácia contra Jailbreak | Moderada (modelos podem ser “enganados” pela matemática interna). | Altíssima (validação determinística e semântica externa). |
Visibilidade e Auditoria com CloudWatch
Uma política de segurança só é útil se puder ser auditada. Cada vez que um Guardrail é acionado, o Bedrock emite logs detalhados para o Amazon CloudWatch e Amazon S3. Esses logs documentam exatamente o que foi bloqueado, qual filtro foi acionado (ex: Filtro de Ódio, Detecção de PII, Tópico Negado) e qual foi o input original.
Equipes de DevSecOps utilizam esses logs para criar dashboards que mostram em tempo real as tentativas de ataque aos agentes de IA da empresa, ajustando as políticas defensivas de forma proativa.
Conclusão
A adoção corporativa de IA Generativa não pode ser um salto no escuro. O Amazon Bedrock Guardrails fornece os “freios” necessários para que as suas equipes de desenvolvimento possam acelerar a inovação. Ao desacoplar a governança do modelo de linguagem em si, você ganha a flexibilidade de trocar de LLMs no futuro sem precisar reconstruir toda a sua postura de segurança. Se a sua aplicação está em produção hoje sem essa camada de interceptação, você está assumindo um risco regulatório e de marca totalmente desnecessário.
Sobre a KXC Partner
A KXC Partner apoia empresas na evolução de sua maturidade em nuvem, com foco em governança, otimização de custos, segurança e automação.
Acompanhe nosso blog para mais conteúdos técnicos e estratégicos sobre AWS e transformação digital.