Como a nova integração entre Knowledge Bases e o S3 Tables elimina a necessidade de SQL complexo, permitindo que áreas de negócios consultem o Data Lake em linguagem natural.
O Efeito Gargalo da Engenharia de Dados
Por muitos anos, a arquitetura de dados corporativos viveu um paradoxo. Armazenamos Petabytes de informações valiosas no Amazon S3, estruturamos tudo em formatos eficientes (como Apache Iceberg via S3 Tables) e criamos Data Lakehouses de altíssima performance. No entanto, o acesso a esses dados continuou refém de um gargalo humano: a linguagem SQL.
Quando um analista de marketing, um diretor financeiro ou um gerente de produto precisava responder a uma pergunta simples como “Qual foi a variação de receita da campanha X na região Sul durante o último trimestre?”, eles não podiam perguntar ao sistema. Eles precisavam abrir um ticket no Jira para a equipe de Engenharia de Dados. O engenheiro, já sobrecarregado, demorava dias para priorizar a tarefa, entender a regra de negócio, escrever a query SQL, validar e entregar um dashboard. O Time-to-Insight (tempo até o insight) era lento e ineficiente.
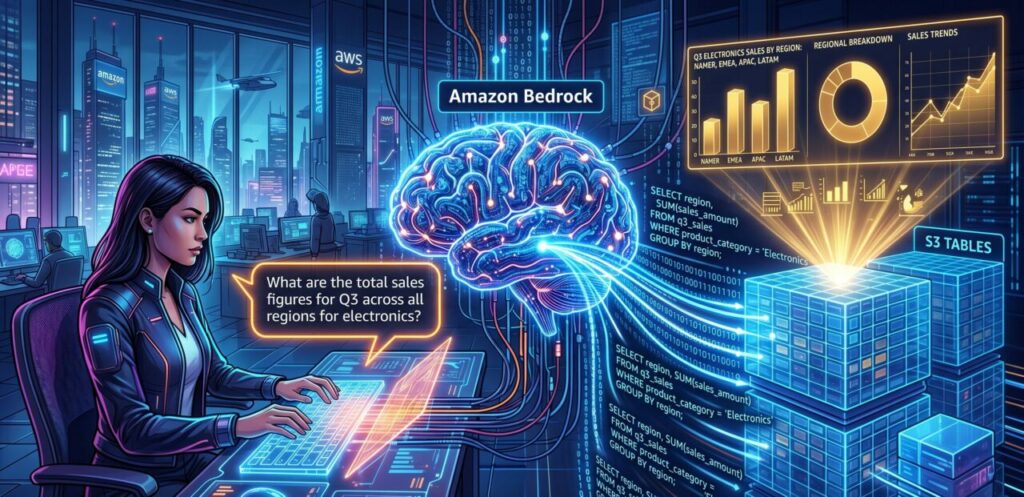
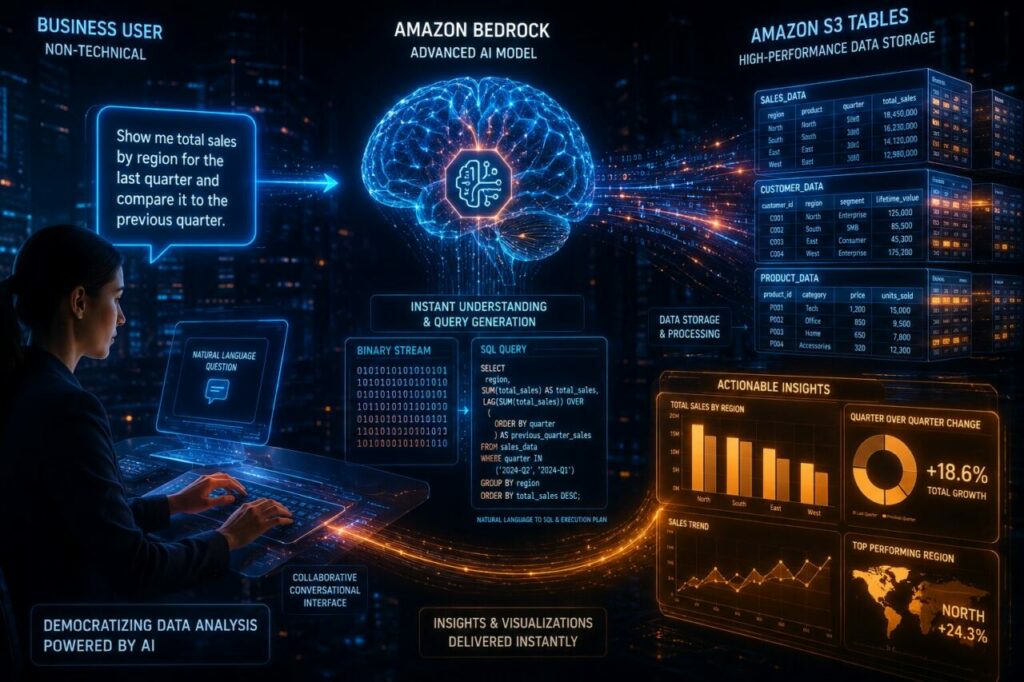
Com a atualização lançada esta semana, a AWS resolveu essa dor na raiz. A integração nativa entre o Amazon Bedrock Knowledge Bases e o Amazon S3 Tables transforma o seu Data Lake em um sistema interativo. Agora, a sua equipe de negócios pode fazer perguntas complexas em linguagem natural e receber respostas precisas extraídas diretamente dos dados estruturados, em segundos.
Entendendo as Peças: S3 Tables e Knowledge Bases
Para compreender a mágica por trás dessa funcionalidade, precisamos revisitar os dois componentes arquitetônicos envolvidos:
- Amazon S3 Tables: Lançado como a evolução do armazenamento tabular no S3, ele gerencia formatos de tabela abertos (como Apache Iceberg) de forma totalmente gerenciada. Ele entrega performance otimizada e forte consistência transacional diretamente no armazenamento de objetos.
- Amazon Bedrock Knowledge Bases: Originalmente famoso por orquestrar fluxos de Retrieval-Augmented Generation (RAG) para dados não-estruturados (como PDFs e documentos de texto), as Bases de Conhecimento agora ganharam a habilidade semântica de compreender esquemas de banco de dados e dados tabulares.
Arquitetura Text-to-SQL sob o Capô
A grande dúvida dos arquitetos de nuvem é: “Como o LLM não alucina ao consultar um banco de dados financeiro?”
A integração S3 Tables + Bedrock não envia os seus Petabytes de dados reais para o modelo de linguagem. Em vez disso, o sistema opera utilizando uma técnica avançada de Text-to-SQL baseada em contexto seguro. O fluxo ocorre em quatro etapas determinísticas:
- Ingestão Semântica do Schema: Ao conectar o S3 Tables ao Bedrock, o Knowledge Base lê os metadados das suas tabelas (nomes de tabelas, tipos de colunas, relacionamentos e descrições). Ele vetoriza apenas o dicionário de dados, não os dados brutos.
- Processamento do Prompt: O usuário faz uma pergunta em linguagem natural (ex: “Liste os top 5 clientes com maior volume de compras canceladas este mês”).
- Geração da Query (Text-to-SQL): O modelo fundacional (ex: Anthropic Claude 3.5 Sonnet) analisa a pergunta e, utilizando o conhecimento prévio do seu esquema de dados, escreve uma query SQL perfeitamente otimizada e sintaticamente correta para o dialeto do S3 Tables.
- Execução e Resumo: A query SQL é executada automaticamente pelo motor de análise nativo (como o Amazon Athena integrado). O resultado tabular bruto (as linhas do banco de dados) é devolvido ao Bedrock, que então formula uma resposta em linguagem natural clara e amigável para o usuário final, incluindo a tabela de dados como referência.
Eliminação de Alucinações com Esquemas Anotados
O segredo para uma taxa de sucesso alta no Text-to-SQL corporativo é o contexto. Um modelo de linguagem não tem como adivinhar que a coluna STS_COD significa “Status do Pedido”. Para blindar a operação contra alucinações de dados, a arquitetura incentiva que os engenheiros de dados adicionem comentários descritivos nos metadados do S3 Tables. Ao descrever as colunas (ex: “Esta coluna armazena o lucro líquido descontando impostos estaduais”), o Bedrock ingere essa inteligência de negócios. Assim, quando o usuário fizer uma pergunta indireta, o modelo saberá exatamente quais junções (JOINs) e agregações (GROUP BY) usar na query invisível.
DevSecOps: Governança e Segurança em Primeiro Lugar
A democratização do acesso aos dados exige governança estrita. Se o CEO e um estagiário fizerem a mesma pergunta para o agente do Bedrock, as respostas podem e devem ser diferentes, dependendo de quem está perguntando.
Como a execução da query ocorre no plano de dados da AWS, toda a arquitetura de integração respeita rigorosamente as permissões do AWS Identity and Access Management (IAM) e do AWS Lake Formation. O Bedrock assume a identidade do usuário (ou da role invocadora) ao disparar a consulta SQL. Se o usuário não tem permissão para visualizar a coluna Salario_Base na tabela do S3 Tables, a query falhará na camada de dados ou omitirá as informações proibidas, e o LLM informará educadamente que não pode acessar aqueles registros. É a garantia do Princípio do Privilégio Mínimo estendido à IA Generativa.
Conclusão
A integração do Amazon S3 Tables com o Bedrock Knowledge Bases é um marco na evolução do Data Mesh corporativo. Ela desamarra os engenheiros de dados de tarefas repetitivas de extração e relatórios básicos, permitindo que foquem na construção de pipelines e arquiteturas preditivas. Ao mesmo tempo, empodera as áreas de negócios com Self-Service Analytics real. Em 2026, a habilidade mais importante para analisar Petabytes de dados não é mais o domínio da sintaxe SQL, mas simplesmente saber fazer a pergunta certa em sua própria língua.
Sobre a KXC Partner
A KXC Partner apoia empresas na evolução de sua maturidade em nuvem, com foco em governança, otimização de custos, segurança e automação.
Acompanhe nosso blog para mais conteúdos técnicos e estratégicos sobre AWS e transformação digital.